【注意】最后更新于 May 2, 2022,文中内容可能已过时,请谨慎使用。
1.介绍
Colly是Golang世界中最知名的Web爬虫框架,它提供简洁的 API,拥有强劲的性能、可以自动处理 cookie&session、提供灵活的扩展机制,同时支持分布式抓取和多种存储后端(如内存、Redis、MongoDB等)。
2.安装
1
2
|
// 下载最新版本
go get -u github.com/gocolly/colly/v2
|
3. 快速入门
3.1 语法模板
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
// 简单使用模板示例
func collyUseTemplate() {
// 创建采集器对象
collector := colly.NewCollector()
// 发起请求之前调用
collector.OnRequest(func(request *colly.Request) {
fmt.Println("发起请求之前调用...")
})
// 请求期间发生错误,则调用
collector.OnError(func(response *colly.Response, err error) {
fmt.Println("请求期间发生错误,则调用:",err)
})
// 收到响应后调用
collector.OnResponse(func(response *colly.Response) {
fmt.Println("收到响应后调用:",response.Request.URL)
})
//OnResponse如果收到的内容是HTML ,则在之后调用
collector.OnHTML("#position_shares table", func(element *colly.HTMLElement) {
// todo 解析html内容
})
// url:请求具体的地址
err := collector.Visit("请求具体的地址")
if err != nil {
fmt.Println("具体错误:",err)
}
}
|
3.2 回调函数说明
- OnRequest: 在发起请求之前调用。
- OnError: 如果请求期间发生错误,则调用。
- OnResponse:收到回复后调用。
- OnHTML: 解析HTML内容 ,在
OnResponse之后调用。
- OnXML: 如果收到的响应内容是XML 调用它。写爬虫基本用不到
- OnScraped:在OnXML/OnHTML回调完成后调用。不过官网写的是
Called after OnXML callbacks,实际上对于OnHTML也有效,大家可以注意一下。
3.3 回调函数注册顺序
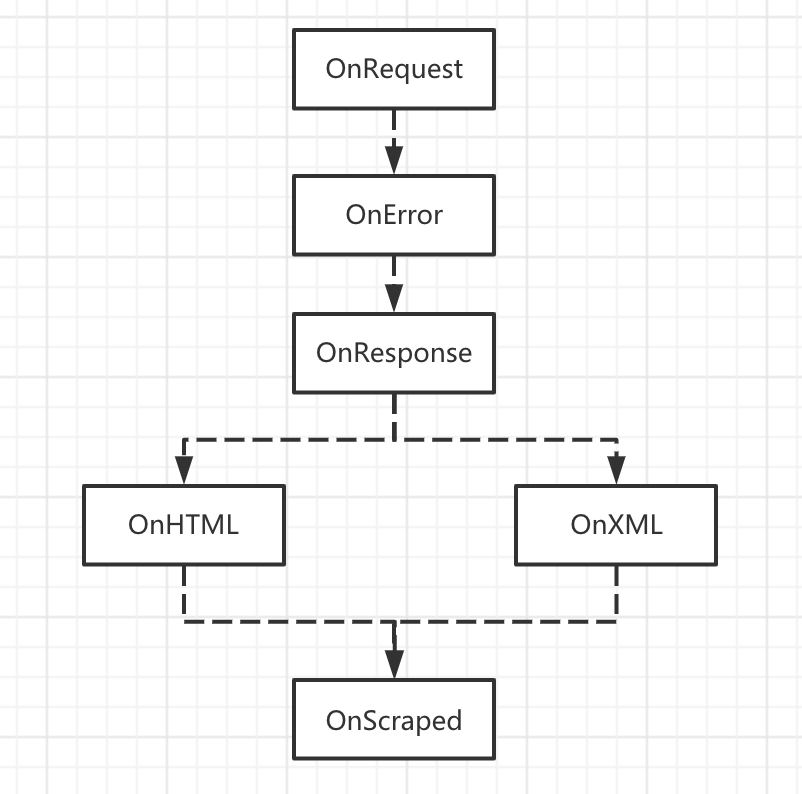
3.4 使用示例
需求: 抓取豆瓣小说榜单数据
1. 分析网页

2. 逻辑分析
- 第一步: 找到对应的
ul
- 第二步: 遍历
ul,然后取出里面没一个li的信息
3. 代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
package collyDemo
import (
"fmt"
"github.com/gocolly/colly/v2"
"strings"
)
// 豆瓣书榜单
func DouBanBook() error {
// 创建 Collector 对象
collector := colly.NewCollector()
// 在请求之前调用
collector.OnRequest(func(request *colly.Request) {
fmt.Println("回调函数OnRequest: 在请求之前调用")
})
// 请求期间发生错误,则调用
collector.OnError(func(response *colly.Response, err error) {
fmt.Println("回调函数OnError: 请求错误",err)
})
// 收到响应后调用
collector.OnResponse(func(response *colly.Response) {
fmt.Println("回调函数OnResponse: 收到响应后调用")
})
//OnResponse如果收到的内容是HTML ,则在之后调用
collector.OnHTML("ul[class='subject-list']", func(element *colly.HTMLElement) {
// 遍历li
element.ForEach("li", func(i int, el *colly.HTMLElement) {
// 获取封面图片
coverImg := el.ChildAttr("div[class='pic'] > a[class='nbg'] > img","src")
// 获取书名
bookName := el.ChildText("div[class='info'] > h2")
// 获取发版信息,并从中解析出作者名称
authorInfo := el.ChildText("div[class='info'] > div[class='pub']")
split := strings.Split(authorInfo, "/")
author := split[0]
fmt.Printf("封面: %v 书名:%v 作者:%v\n",coverImg,trimSpace(bookName),author)
})
})
// 发起请求
return collector.Visit("https://book.douban.com/tag/小说")
}
// 删除字符串中的空格信息
func trimSpace(str string) string {
// 替换所有的空格
str = strings.ReplaceAll(str," ","")
// 替换所有的换行
return strings.ReplaceAll(str,"\n","")
}
|
4. 运行结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
回调函数OnRequest: 在请求之前调用
回调函数OnResponse: 收到响应后调用
封面: https://img9.doubanio.com/view/subject/s/public/s27279654.jpg 书名:活着 作者:余华
封面: https://img1.doubanio.com/view/subject/s/public/s33880929.jpg 书名:字母表谜案 作者:大山诚一郎
封面: https://img1.doubanio.com/view/subject/s/public/s24514468.jpg 书名:白夜行 作者:[日] 东野圭吾
封面: https://img2.doubanio.com/view/subject/s/public/s29651121.jpg 书名:房思琪的初恋乐园 作者:林奕含
封面: https://img1.doubanio.com/view/subject/s/public/s33834057.jpg 书名:文城 作者:余华
封面: https://img3.doubanio.com/view/subject/s/public/s27237850.jpg 书名:百年孤独 作者:[哥伦比亚] 加西亚·马尔克斯
封面: https://img9.doubanio.com/view/subject/s/public/s33944156.jpg 书名:蛤蟆先生去看心理医生 作者:【英】罗伯特·戴博德
封面: https://img1.doubanio.com/view/subject/s/public/s1070959.jpg 书名:红楼梦 作者:[清] 曹雪芹 著、高鹗 续
封面: https://img9.doubanio.com/view/subject/s/public/s33821754.jpg 书名:克拉拉与太阳 作者:[英] 石黑一雄
封面: https://img2.doubanio.com/view/subject/s/public/s1103152.jpg 书名:小王子 作者:[法] 圣埃克苏佩里
封面: https://img2.doubanio.com/view/subject/s/public/s27264181.jpg 书名:解忧杂货店 作者:[日] 东野圭吾
封面: https://img1.doubanio.com/view/subject/s/public/s2768378.jpg 书名:三体:“地球往事”三部曲之一 作者:刘慈欣
封面: https://img3.doubanio.com/view/subject/s/public/s1727290.jpg 书名:追风筝的人 作者:[美] 卡勒德·胡赛尼
封面: https://img2.doubanio.com/view/subject/s/public/s11284102.jpg 书名:霍乱时期的爱情 作者:[哥伦比亚] 加西亚·马尔克斯
封面: https://img3.doubanio.com/view/subject/s/public/s24575140.jpg 书名:许三观卖血记 作者:余华
封面: https://img1.doubanio.com/view/subject/s/public/s4371408.jpg 书名:1984 作者:[英] 乔治·奥威尔
封面: https://img9.doubanio.com/view/subject/s/public/s4468484.jpg 书名:局外人 作者:[法] 阿尔贝·加缪
封面: https://img9.doubanio.com/view/subject/s/public/s28357056.jpg 书名:三体全集:地球往事三部曲 作者:刘慈欣
封面: https://img9.doubanio.com/view/subject/s/public/s29799055.jpg 书名:云边有个小卖部 作者:张嘉佳
封面: https://img3.doubanio.com/view/subject/s/public/s33718940.jpg 书名:夜晚的潜水艇 作者:陈春成
|
4. 配置采集器
4.1 配置预览

4.2 部分配置说明
AllowedDomains: 设置收集器使用的域白名单,设置后不在白名单内链接,报错:Forbidden domain。AllowURLRevisit: 设置收集器允许对同一 URL 进行多次下载。Async: 设置收集器为异步请求,需很Wait()配合使用。Debugger: 开启Debug,开启后会打印请求日志。MaxDepth: 设置爬取页面的深度。UserAgent: 设置收集器使用的用户代理。MaxBodySize : 以字节为单位设置检索到的响应正文的限制。IgnoreRobotsTxt: 忽略目标机器中的robots.txt声明。
4.3 创建采集器
1
2
3
4
5
6
7
8
9
10
|
collector := colly.NewCollector(
colly.AllowedDomains("www.baidu.com",".baidu.com"),//白名单域名
colly.AllowURLRevisit(),//允许对同一 URL 进行多次下载
colly.Async(true),//设置为异步请求
colly.Debugger(&debug.LogDebugger{}),// 开启debug
colly.MaxDepth(2),//爬取页面深度,最多为两层
colly.MaxBodySize(1024 * 1024),//响应正文最大字节数
colly.UserAgent("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36"),
colly.IgnoreRobotsTxt(),//忽略目标机器中的`robots.txt`声明
)
|
5. 常用解析函数
colly爬取到页面之后,又该怎么解析Html内容呢?实际上使用goquery包解析这个页面,而colly.HTMLElement其实就是对goquery.Selection的简单封装:
1
2
3
4
5
6
7
8
9
10
11
|
// colly.HTMLElement结构体
type HTMLElement struct {
Name string
Text string
attributes []html.Attribute
Request *Request
Response *Response
// 对goquery封装
DOM *goquery.Selection
Index int
}
|
5.1 Attr
1. 函数说明
1
2
|
//返回当前元素的属性
func (h *HTMLElement) Attr(k string) string
|
2. 使用示例

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
// 返回当前元素的属性
func TestUseAttr(t *testing.T) {
collector := colly.NewCollector()
// 定位到div[class='nav-logo'] > a标签元素
collector.OnHTML("div[class='nav-logo'] > a", func(element *colly.HTMLElement) {
fmt.Printf("href:%v\n",element.Attr("href"))
})
_ = collector.Visit("https://book.douban.com/tag/小说")
}
/**输出
=== RUN TestUseAttr
href:https://book.douban.com
--- PASS: TestUseAttr (0.66s)
PASS
*/
|
5.2 ChildAttr&ChildAttrs
1. 函数说明
1
2
3
4
|
// 返回`goquerySelector`选择的第一个子元素的`attrName`属性;
func (h *HTMLElement) ChildAttr(goquerySelector, attrName string) string
// 返回`goquerySelector`选择的所有子元素的`attrName`属性,以`[]string`返回;
func (h *HTMLElement) ChildAttrs(goquerySelector, attrName string) []string
|
2. 使用示例

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
func TestChildAttrMethod(t *testing.T) {
collector := colly.NewCollector()
collector.OnError(func(response *colly.Response, err error) {
fmt.Println("OnError",err)
})
// 解析Html
collector.OnHTML("body", func(element *colly.HTMLElement) {
// 获取第一个子元素(div)的class属性
fmt.Printf("ChildAttr:%v\n",element.ChildAttr("div","class"))
// 获取所有子元素(div)的class属性
fmt.Printf("ChildAttrs:%v\n",element.ChildAttrs("div","class"))
})
err := collector.Visit("https://liuqh.icu/a.html")
if err != nil {
fmt.Println("err",err)
}
}
/**输出
=== RUN TestChildAttrMethod
ChildAttr:div1
ChildAttrs:[div1 sub1 div2 div3]
--- PASS: TestChildAttrMethod (0.29s)
PASS
*/
|
5.3 ChildText & ChildTexts
1. 函数说明
1
2
3
4
|
// 拼接goquerySelector选择的子元素的文本内容并返回
func (h *HTMLElement) ChildText(goquerySelector string) string
// 返回goquerySelector选择的子元素的文本内容组成的切片,以[]string返回。
func (h *HTMLElement) ChildTexts(goquerySelector string) []string
|
2. 使用示例
a. 待解析的Html:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
<html>
<head>
<title>测试</title>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
</head>
<body>
<div class="div1">
<div class="sub1">内容1</div>
</div>
<div class="div2">内容2</div>
<div class="div3">内容3</div>
</body>
</html>
|
b. 解析代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
// 测试使用ChildText和ChildTexts
func TestChildTextMethod(t *testing.T) {
collector := colly.NewCollector()
collector.OnError(func(response *colly.Response, err error) {
fmt.Println("OnError",err)
})
//
collector.OnHTML("body", func(element *colly.HTMLElement) {
// 获取第一个子元素(div)的class属性
fmt.Printf("ChildText:%v\n",element.ChildText("div"))
// 获取所有子元素(div)的class属性
fmt.Printf("ChildTexts:%v\n",element.ChildTexts("div"))
})
err := collector.Visit("https://liuqh.icu/a.html")
if err != nil {
fmt.Println("err",err)
}
}
/**输出
=== RUN TestChildTextMethod
ChildText:内容1
内容1内容2内容3
ChildTexts:[内容1 内容1 内容2 内容3]
--- PASS: TestChildTextMethod (0.28s)
PASS
*/
|
5.4 ForEach
1. 函数说明
1
2
|
//对每个`goquerySelector`选择的子元素执行回调`callback`
func (h *HTMLElement) ForEach(goquerySelector string, callback func(int, *HTMLElement))
|
2. 使用示例
a. 待解析Html:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
<html>
<head>
<title>测试</title>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
</head>
<body>
<ul class="demo">
<li>
<span class="name">张三</span>
<span class="age">18</span>
<span class="home">北京</span>
</li>
<li>
<span class="name">李四</span>
<span class="age">22</span>
<span class="home">南京</span>
</li>
<li>
<span class="name">王五</span>
<span class="age">29</span>
<span class="home">天津</span>
</li>
</ul>
</body>
</html>
|
b. 解析代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
func TestForeach(t *testing.T) {
collector := colly.NewCollector()
collector.OnHTML("ul[class='demo']", func(element *colly.HTMLElement) {
element.ForEach("li", func(_ int, el *colly.HTMLElement) {
name := el.ChildText("span[class='name']")
age := el.ChildText("span[class='age']")
home := el.ChildText("span[class='home']")
fmt.Printf("姓名: %s 年龄:%s 住址: %s \n",name,age,home)
})
})
_ = collector.Visit("https://liuqh.icu/a.html")
}
/**输出
=== RUN TestForeach
姓名: 张三 年龄:18 住址: 北京
姓名: 李四 年龄:22 住址: 南京
姓名: 王五 年龄:29 住址: 天津
--- PASS: TestForeach (0.36s)
PASS
*/
|
5.5 Unmarshal
1. 函数说明
1
2
|
// 通过给结构体字段指定 goquerySelector 格式的 tag,可以将HTMLElement对象Unmarshal 到一个结构体实例中
func (h *HTMLElement) Unmarshal(v interface{}) error
|
2. 使用示例
a. 待解析Html
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
<html>
<head>
<title>测试</title>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
</head>
<body>
<div class="book">
<span class="title"><a href="https://liuqh.icu">红楼梦</a></span>
<span class="autor">曹雪芹 </span>
<ul class="category">
<li>四大名著</li>
<li>文学著作</li>
<li>古典长篇章回小说</li>
<li>四大小说名著之首</li>
</ul>
<span class="price">59.70元</span>
</div>
</body>
</html>
|
b. 解析代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
// 定义结构体
type Book struct {
Name string `selector:"span.title"`
Link string `selector:"span > a" attr:"href"`
Author string `selector:"span.autor"`
Reviews []string `selector:"ul.category > li"`
Price string `selector:"span.price"`
}
func TestUnmarshal(t *testing.T) {
// 声明结构体
var book Book
collector := colly.NewCollector()
collector.OnHTML("body", func(element *colly.HTMLElement) {
err := element.Unmarshal(&book)
if err != nil {
fmt.Println("解析失败:",err)
}
fmt.Printf("结果:%+v\n",book)
})
_ = collector.Visit("https://liuqh.icu/a.html")
}
/***输出
=== RUN TestUnmarshal
结果:{Name:红楼梦 Link:https://liuqh.icu Author:曹雪芹 Reviews:[四大名著 文学著作 古典长篇章回小说 四大小说名著之首] Price:59.70元}
--- PASS: TestUnmarshal (0.27s)
PASS
*/
|
6.常用选择器
6.1 html内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
<html>
<head>
<title>测试</title>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
</head>
<body>
<!-- 演示ID选择器 -->
<div id="title">标题ABC</div>
<!-- 演示class选择器 -->
<div class="desc">这是一段描述</div>
<!-- 演示相邻选择器 -->
<span>好好学习!</span>
<!-- 演示父子选择器 -->
<div class="parent">
<!-- 演示兄弟选择器 -->
<p class="childA">老大</p>
<p class="childB">老二</p>
</div>
<!-- 演示同时筛选多个选择器 -->
<span class="context1">武松上山</span>
<span class="context2">打老虎</span>
</body>
</html>
|
6.2 使用示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
// 常用选择器使用
func TestSelector(t *testing.T) {
collector := colly.NewCollector()
collector.OnHTML("body", func(element *colly.HTMLElement) {
// ID属性选择器,使用#
fmt.Printf("ID选择器使用: %v \n",element.ChildText("#title"))
// Class属性选择器,使用
fmt.Printf("class选择器使用1: %v \n",element.ChildText("div[class='desc']"))
fmt.Printf("class选择器使用2: %v \n",element.ChildText(".desc"))
// 相邻选择器 prev + next: 提取 <span>好好学习!</span>
fmt.Printf("相邻选择器: %v \n",element.ChildText("div[class='desc'] + span"))
// 父子选择器: parent > child,提取:<div class="parent">下所有子元素
fmt.Printf("父子选择器: %v \n",element.ChildText("div[class='parent'] > p"))
// 兄弟选择器 prev ~ next , 提取:<p class="childB">老二</p>
fmt.Printf("兄弟选择器: %v \n",element.ChildText("p[class='childA'] ~ p"))
// 同时选中多个,用,
fmt.Printf("同时选中多个1: %v \n",element.ChildText("span[class='context1'],span[class='context2']"))
fmt.Printf("同时选中多个2: %v \n",element.ChildText(".context1,.context2"))
})
_ = collector.Visit("https://liuqh.icu/a.html")
}
/**输出
=== RUN TestSelector
ID选择器使用: 标题ABC
class选择器使用1: 这是一段描述
class选择器使用2: 这是一段描述
相邻选择器: 好好学习!
父子选择器: 老大老二
兄弟选择器: 老二
同时选中多个1: 武松上山打老虎
同时选中多个2: 武松上山打老虎
--- PASS: TestSelector (0.31s)
PASS
*/
|
7. 过滤器
7.1 第一个子元素(first-child & first-of-type)
1. 过滤器说明
| 过滤器 |
说明 |
:first-child |
筛选出父元素的第一个子元素,不分区子元素类型 |
:first-of-type |
筛选出父元素的第一个指定类型子元素 |
2. html内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
<html>
<head>
<title>测试</title>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
</head>
<body>
<div class="parent">
<!--因为这里的p不是第一个子元素,不会被first-child筛选到-->
<span>第一个不是p标签</span>
<p>老大</p>
<p>老二</p>
</div>
<div class="name">
<p>张三</p>
<p>小米</p>
</div>
</body>
</html>
|
3. 代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
// 常用过滤器使用first-child & first-of-type
func TestFilterFirstChild(t *testing.T) {
collector := colly.NewCollector()
collector.OnHTML("body", func(element *colly.HTMLElement) {
// 只会筛选父元素下第一个子元素是<p>..</p>
fmt.Printf("first-child: %v \n",element.ChildText("p:first-child"))
// 会筛选父元素下第一个子元素类型是<p>..</p>
fmt.Printf("first-of-type: %v \n",element.ChildText("p:first-of-type"))
})
_ = collector.Visit("https://liuqh.icu/a.html")
}
/**输出
=== RUN TestFilterFirstChild
first-child: 张三
first-of-type: 老大张三
--- PASS: TestFilterFirstChild (0.51s)
PASS
*/
|
7.2 最后一个子元素(last-child & last-of-type)
1. 过滤器说明
| 过滤器 |
说明 |
:last-child |
筛选出父元素的最后一个子元素,不分区子元素类型 |
:last-of-type |
筛选出父元素的最后一个指定类型子元素 |
使用方法和上面筛选第一个子元素一样,不在啰嗦。
7.3 第x个子元素(nth-child & nth-of-type)
1. 过滤器说明
| 过滤器 |
说明 |
nth-child(n) |
筛选出的元素是其父元素的第n个元素,n以1开始。
所以:nth-child(1) = :first-child |
nth-of-type(n) |
和nth-child一样,只不过它筛选的是同类型的第n个元素,
所以:nth-of-type(1) = :first-of-type |
nth-last-child(n) |
和nth-child(n)一样,顺序是倒序 |
nth-last-of-type(n) |
和nth-of-type(n)一样,顺序是倒序 |
2. 使用示例
html内容和上面(7.1中)的html内容一样。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
// 过滤器第x个元素
func TestFilterNth(t *testing.T) {
collector := colly.NewCollector()
collector.OnHTML("body", func(element *colly.HTMLElement) {
//<div class="parent">下的第一个子元素
nthChild := element.ChildText("div[class='parent'] > :nth-child(1)")
fmt.Printf("nth-child(1): %v \n",nthChild)
//<div class="parent">下的第一个p子元素
nthOfType := element.ChildText("div[class='parent'] > p:nth-of-type(1)")
fmt.Printf("nth-of-type(1): %v \n",nthOfType)
// div class="parent">下的最后一个子元素
nthLastChild := element.ChildText("div[class='parent'] > :nth-last-child(1)")
fmt.Printf("nth-last-child(1): %v \n",nthLastChild)
//<div class="parent">下的最后一个p子元素
nthLastOfType := element.ChildText("div[class='parent'] > p:nth-last-of-type(1)")
fmt.Printf("nth-last-of-type(1): %v \n",nthLastOfType)
})
_ = collector.Visit("https://liuqh.icu/a.html")
}
/**输出
=== RUN TestFilterNth
nth-child(1): 第一个不是p标签
nth-of-type(1): 老大
nth-last-child(1): 老二
nth-last-of-type(1): 老二
--- PASS: TestFilterNth (0.29s)
PASS
*/
|
7.4 仅有一个子元素(only-child & only-of-type)
1. 过滤器说明
| 过滤器 |
说明 |
:only-child |
筛选其父元素下只有个子元素 |
:on-of-type |
筛选其父元素下只有个指定类型的子元素 |
2. html内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
<html>
<head>
<title>测试</title>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
</head>
<body>
<div class="parent">
<span>我是span标签</span>
</div>
<div class="name">
<p>我是p标签</p>
</div>
</body>
</html>
|
3. 使用示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
// 过滤器只有一个元素
func TestFilterOnly(t *testing.T) {
collector := colly.NewCollector()
collector.OnHTML("body", func(element *colly.HTMLElement) {
// 匹配其子元素:有且只有一个标签的
onlyChild := element.ChildTexts("div > :only-child")
fmt.Printf("onlyChild: %v \n",onlyChild)
// 匹配其子元素:有且只有一个 p 标签的
nthOfType := element.ChildTexts("div > p:only-of-type")
fmt.Printf("nth-of-type(1): %v \n",nthOfType)
})
_ = collector.Visit("https://liuqh.icu/a.html")
}
/**输出
=== RUN TestFilterOnly
onlyChild: [我是span标签 我是p标签]
nth-of-type(1): [我是p标签]
--- PASS: TestFilterOnly (0.29s)
PASS
*/
|
7.5 内容匹配(contains)
1. html内容
1
2
3
4
5
6
7
8
9
10
|
<html>
<head>
<title>测试</title>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
</head>
<body>
<a href="https://www.baidu.com">百度</a>
<a href="https://cn.bing.com">必应</a>
</body>
</html>
|
2. 使用示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
func TestFilterContext(t *testing.T) {
collector := colly.NewCollector()
collector.OnHTML("body", func(element *colly.HTMLElement) {
// 内容匹配
attr1 := element.ChildAttr("a:contains(百度)", "href")
attr2 := element.ChildAttr("a:contains(必应)", "href")
fmt.Printf("百度: %v \n",attr1)
fmt.Printf("必应: %v \n",attr2)
})
_ = collector.Visit("https://liuqh.icu/a.html")
}
/**输出
=== RUN TestFilterContext
百度: https://www.baidu.com
必应: https://cn.bing.com
--- PASS: TestFilterContext (0.31s)
PASS
*/
|
8. 爬取限速
有时候并发请求太多,网站会限制访问。这时就需要使用LimitRule了。说白了,LimitRule就是限制访问速度和并发量的:
1
2
3
4
5
6
7
|
type LimitRule struct {
DomainRegexp string // 匹配域名的正则表达式
DomainGlob string // glob 匹配模式
Delay time.Duration // 请求之间的延迟
RandomDelay time.Duration // 添加额外的随机延迟
Parallelism int // 设置并发数
}
|
@注意: DomainRegexp和DomainGlob,两个参数至少要设置一个,否则报错
更多场景使用示例