【注意】最后更新于 August 7, 2023,文中内容可能已过时,请谨慎使用。
1.介绍
随着哈希表中元素的逐渐增加,哈希的性能会逐渐恶化,所以我们需要更多的桶和更大的内存来保证哈希的读写性能。
2.如何触发
在每次对哈希表赋值时,都会调用 runtime.mapassign 函数,该函数每次都会判断是否需要扩容,主要有两个函数:overLoadFactor和tooManyOverflowBuckets:
1
2
3
4
5
6
7
8
9
10
|
// hash[k]=x表达式,会在编译期间转换成runtime.mapassign 函数的调用
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
// 扩容入口
hashGrow(t, h)
goto again
}
...
}
|
overLoadFactor:主要判断装载因子是否超过6.5tooManyOverflowBuckets:用来判断是否使用了太多溢出桶h.growing():用来判断是否已经处于扩容状态
因为Go语言哈希的扩容不是一个原子的过程,所以 runtime.mapassign 还需要判断当前哈希是否已经处于扩容状态,避免二次扩容造成混乱。
3.扩容方式
根据触发的条件不同,扩容的方式分为两种:
- 第一种:装载因子超过
6.5,则会进行双倍重建
- 第二种:当溢出桶的数量过多时,会进行等量重建
3.1 等量扩容
当我们对map不断进行新增和删除时,桶中可能会出现很多断断续续的空位,这些空位会导致连续的bmap溢出桶很长,对应的扫描时间也会变长,查询性能就会下降。这种扩容实际上是一种整理,把后置位的数据整理到前面。
3.2 双倍重建
两倍重建是为了让map存储更多的数据,在双倍重建时,我们还需要解决旧桶中的数据要转移到某一个新桶中的问题,其中有一个非常重要的原则:如果数据的 hash&bucketMask[当前新桶所在的位置]小于或等于旧桶的大小,则此数据必须转移到和旧桶位置完全对应的新桶中去,理由是当前key所在新桶的序号与旧桶是完全相同的。
4.扩容流程
4.1 扩容核心函数
扩容需要处理的问题是,扩容后,map中原本的数据重新放到扩容后的map中,即数据迁移问题,golang中map扩容时核心函数有如下几个:
hashGrow:决定扩容方式,负责初始化新的桶,以及设备扩容后的map的各个字段growWork:每调用一次growWork函数,都至多会迁移两个桶的数据evacuate:真正负责迁移数据的函数,会负责迁移指定桶中的数据advanceEvacuationMark:收尾工作,增加nevacuate,如果所有的oldbuckets都迁移完成了,会摘除oldbuckets
4.2 hashGrow
重建时需要调用hashGrow函数,如果负载因子超载,则会进行双倍重建。当溢出桶的数量过多时,会进行等量重建。新桶会存储到buckets字段,旧桶会存储到oldbuckets字段,map中extra字段的溢出桶也进行同样的转移。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
func hashGrow(t *maptype, h *hmap) {
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
// 旧数据存到旧桶
oldbuckets := h.buckets
// 创建一组新桶和溢出桶
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
h.B += bigger
h.flags = flags
// 旧数据存到旧桶上
h.oldbuckets = oldbuckets
h.buckets = newbuckets
h.nevacuate = 0
h.noverflow = 0
// 原有的溢出桶,存到旧溢出桶
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
h.extra.nextOverflow = nextOverflow
}
|
@注意:这里并没有实际执行将旧桶中的数据转移到新桶的过程,数据转移遵循写时复制(copy on write)的规则,只要在真正赋值时,才会选择是否需要进行数据转移,其核心逻辑位于growWork和evacuate函数中。
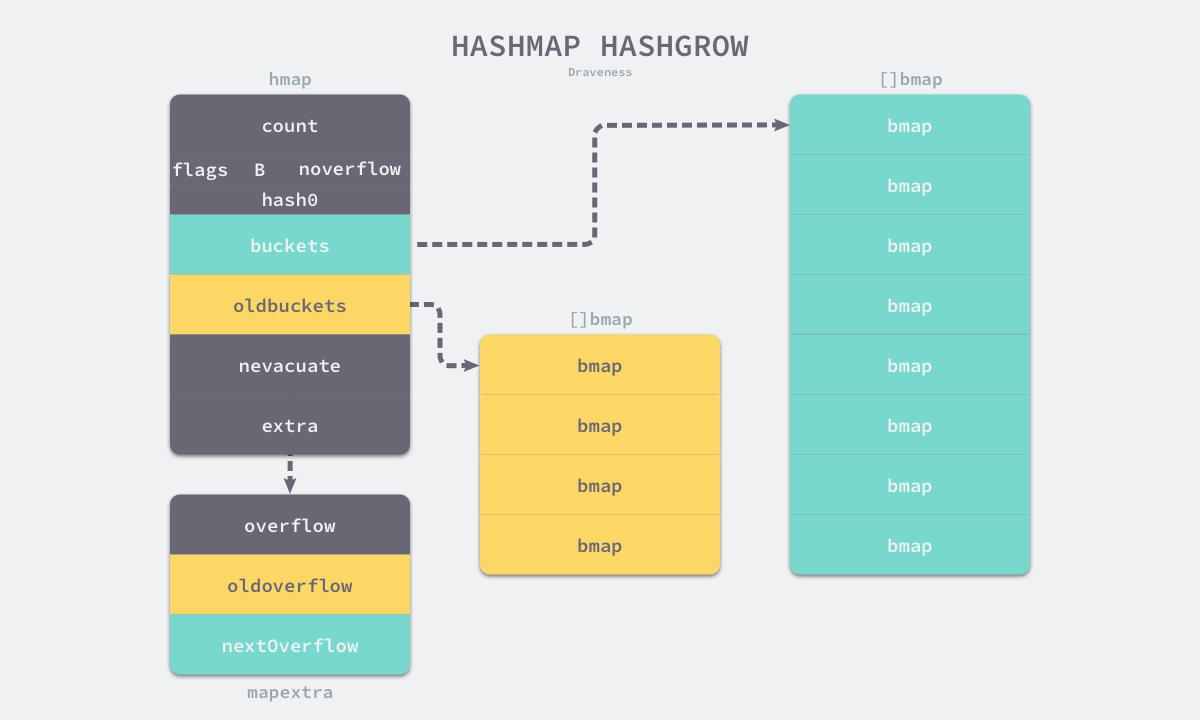
4.3 growWork
growWork函数并不会真正进行数据迁移,它会调用evacuate函数来完成迁移工作,growWork函数每次会迁移至多两个桶的数据,一个是目前需要使用的桶,一个是h.nevacuate桶(这里很重要,在后面判断是否迁移过程中有很大的作用),h.nevacuate记录的是目前至少已经迁移的桶的个数。
1
2
3
4
5
6
7
8
9
10
|
func growWork(t *maptype, h *hmap, bucket uintptr) {
// make sure we evacuate the oldbucket corresponding
// to the bucket we're about to use
evacuate(t, h, bucket&h.oldbucketmask())
// evacuate one more oldbucket to make progress on growing
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}
|
4.4 evacuate
evacuate是真正进行数据迁移的函数,它每次会迁移一个bmap中的数据,简单说,就是遍历旧有buckets中bmap中的数据,将其放到新bmap的对应位置;
在学习evacuate函数前,先记bmap.tophash的几个特殊值,在扩容过程中会使用到:
1
2
3
4
5
6
|
emptyRest = 0 // 表明该位置及其以后的位置都没有数据
emptyOne = 1 // 表明该位置没有数据
evacuatedX = 2 // key/elem是有效的,它已经在扩容过程中被迁移到了更大表的前半部分
evacuatedY = 3 // key/elem是有效的,它已经在扩容过程中被迁移到了更大表的后半部分
evacuatedEmpty = 4 // 该位置没有数据,且已被扩容
minTopHash = 5 // 一个被正常填充的tophash的最小值
|
4.4.1 判断桶的迁移状态
首先会判断这个桶是否已经被迁移过了,或者正在迁移中,如果没有被迁移,才会进行迁移工作,该判断是通过evacuated函数完成的,该函数很简单,只需要判断tophash[0]是否是evacuatedX,evacuatedY,evacuateEmpty即可。
1
2
3
4
|
func evacuated(b *bmap) bool {
h := b.tophash[0]
return h > emptyOne && h < minTopHash
}
|
4.4.2 初始化evacDst结构
初始化evacDst结构,如果是等量扩容,则只会初始化一个,如果是普通扩容,则会初始化两个。runtime.evacuate 会将一个旧桶中的数据分流到两个新桶,所以它会创建两个用于保存分配上下文的runtime.evacDst 结构体,这两个结构体分别指向了一个新桶:
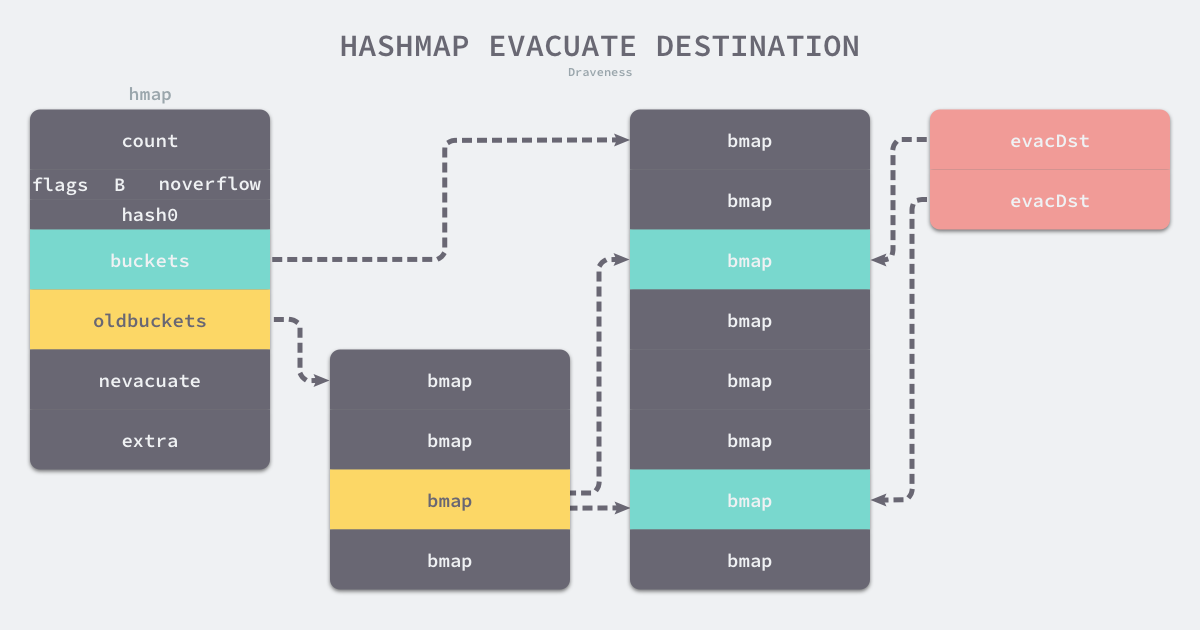
evacDst结构体如下所思:
1
2
3
4
5
6
|
type evacDst struct {
b *bmap // 目标桶
i int // 每个桶有8个位置可以塞数据,这个i可以理解为当前塞了多少个数据
k unsafe.Pointer // 目标桶中key的位置
e unsafe.Pointer // 目标桶中elem的位置
}
|
4.4.3 旧桶元素分流
如果这是等量扩容,那么旧桶与新桶是一对一的关系,所以两个 runtime.evacDst 只会初始化一个,而当哈希表的容量翻倍时,每个旧桶的元素都会分流到新创建的两个桶中,这里仔细分析一下分流元素的逻辑:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
|
...
// 遍历 oldbuckets 对应的 bucket 以及 oveflow
for ; b != nil; b = b.overflow(t) {
//获取当前 bucket 的 key 的起始位置
k := add(unsafe.Pointer(b), dataOffset)
//获取当前 bucket 的 elem 的起始位置
e := add(k, bucketCnt*uintptr(t.keysize))
//遍历当前 bucket 中 8 个 key,elem
for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.keysize)), add(e, uintptr(t.elemsize)) {
top := b.tophash[i]
// 如果为空,则跳过
if isEmpty(top) {
b.tophash[i] = evacuatedEmpty
continue
}
//如果小于 minTopHash ,则表示其已经被转移走了,则 throw
if top < minTopHash {
throw("bad map state")
}
k2 := k
//如果存的是对应 key 的指针,则要获取 key 的地址
if t.indirectkey() {
k2 = *((*unsafe.Pointer)(k2))
}
var useY uint8
// 如果是非等量迁移(双倍重建)
if !h.sameSizeGrow() {
//算出当前 key 的 hash 值
hash := t.hasher(k2, uintptr(h.hash0))
if h.flags&iterator != 0 && !t.reflexivekey() && !t.key.equal(k2, k2) {
useY = top & 1 //让这个 key 50% 概率去 Y 半区
top = tophash(hash)
} else {
if hash&newbit != 0 {
useY = 1
}
}
}
if evacuatedX+1 != evacuatedY || evacuatedX^1 != evacuatedY {
throw("bad evacuatedN")
}
b.tophash[i] = evacuatedX + useY // evacuatedX + 1 == evacuatedY
dst := &xy[useY] // 移动目标
if dst.i == bucketCnt {
dst.b = h.newoverflow(t, dst.b)
dst.i = 0
dst.k = add(unsafe.Pointer(dst.b), dataOffset)
dst.e = add(dst.k, bucketCnt*uintptr(t.keysize))
}
dst.b.tophash[dst.i&(bucketCnt-1)] = top // mask dst.i as an optimization, to avoid a bounds check
if t.indirectkey() {
*(*unsafe.Pointer)(dst.k) = k2 // copy pointer
} else {
typedmemmove(t.key, dst.k, k) // copy elem
}
if t.indirectelem() {
*(*unsafe.Pointer)(dst.e) = *(*unsafe.Pointer)(e)
} else {
typedmemmove(t.elem, dst.e, e)
}
dst.i++
// These updates might push these pointers past the end of the
// key or elem arrays. That's ok, as we have the overflow pointer
// at the end of the bucket to protect against pointing past the
// end of the bucket.
dst.k = add(dst.k, uintptr(t.keysize))
dst.e = add(dst.e, uintptr(t.elemsize))
}
}
...
|
只使用哈希函数是不能定位到具体某一个桶的,哈希函数只会返回很长的哈希,例如:
b72bfae3f3285244c4732ce457cca823bc189e0b,我们还需一些方法将哈希映射到具体的桶上,我们一般都会使用取模或者位操作来获取桶的编号,加入当前哈希中包含4个桶,那么它的桶掩码就是0b11(3),使用位操作就会得到3,我们就会在3号桶中存储该数据。
1
|
0xb72bfae3f3285244c4732ce457cca823bc189e0b & 0b11 #=> 0
|
如果新的哈希表有8个桶,在大多数情况下,原来经过桶掩码0b11结果为3的数据会因为桶掩码增加了一位变成了0b111而分流到新的3和7号桶,所有数据也都会被 runtime.typedmemmove 拷贝到目标桶中:
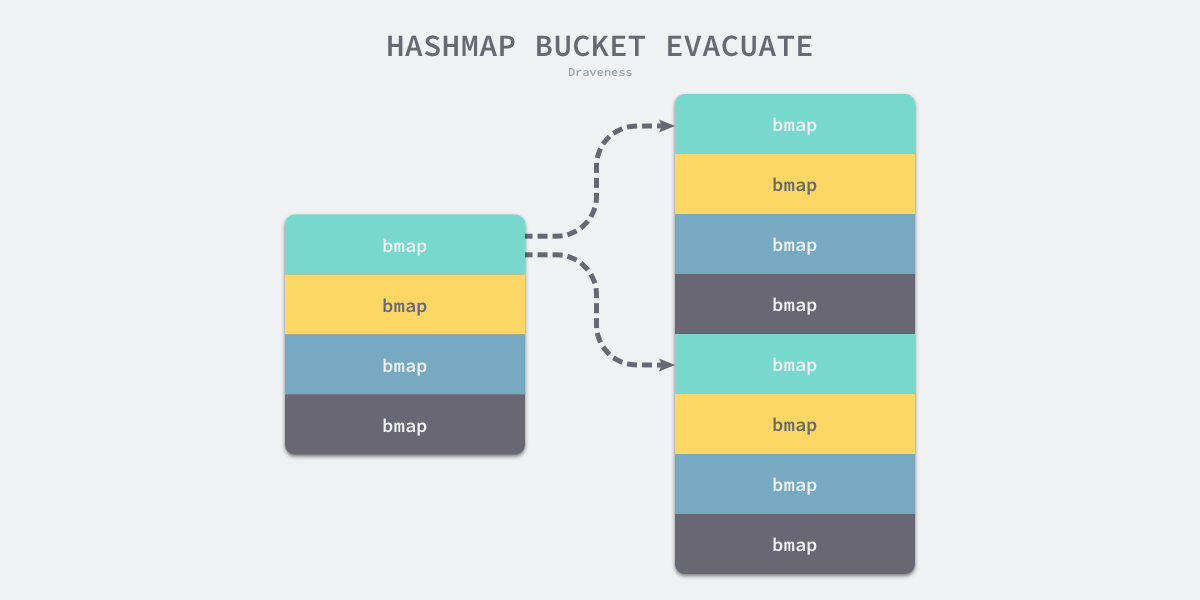
4.5 advanceEvacuationMark
runtime.evacuate 最后会调用 runtime.advanceEvacuationMark 增加哈希的 nevacuate 计数器并在所有的旧桶都被分流后清空哈希的 oldbuckets 和 oldoverflow:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
func advanceEvacuationMark(h *hmap, t *maptype, newbit uintptr) {
h.nevacuate++
// Experiments suggest that 1024 is overkill by at least an order of magnitude.
// Put it in there as a safeguard anyway, to ensure O(1) behavior.
stop := h.nevacuate + 1024
if stop > newbit {
stop = newbit
}
for h.nevacuate != stop && bucketEvacuated(t, h, h.nevacuate) {
h.nevacuate++
}
if h.nevacuate == newbit { // newbit == # of oldbuckets
// 大小增长全部结束。释放老的 bucket array
h.oldbuckets = nil
// 同样可以丢弃老的 overflow buckets
// 如果它们还被迭代器所引用的话
// 迭代器会持有一份指向 slice 的指针
if h.extra != nil {
h.extra.oldoverflow = nil
}
h.flags &^= sameSizeGrow
}
}
|