Go底层探索(四):哈希表map上篇
文章目录
【注意】最后更新于 July 12, 2023,文中内容可能已过时,请谨慎使用。
1.介绍
Go语言中的map又被称为哈希表,是使用频率极高的一种数据结构。哈希表的原理是将多个键/值(key/value)对,分散存储在桶(buckets)中。
通常map的时间复杂度为O(1),通过一个键快速寻找其唯一对应的值value。在许多情况下,哈希表的查找速度明显快于一些搜索树形式的数据结构,被广泛应用于 关联数组、缓存、数据库缓存 等场景中。
如果想要实现一个性能优异的哈希表,需要注意两个关键点 —— 哈希函数和冲突解决方法。
2.哈希函数与碰撞
实现哈希表的关键点在于哈希函数的选择,哈希函数的选择在很大程度上能够决定哈希表的读写性能。在理想情况下,哈希函数应该能够将不同的键映射到不同的索引上,但是在实际使用时,这个理想的效果是不可能实现的。
下面展示两张图,分别示意 完美哈希函数和不均匀哈希函数 计算的结果图:
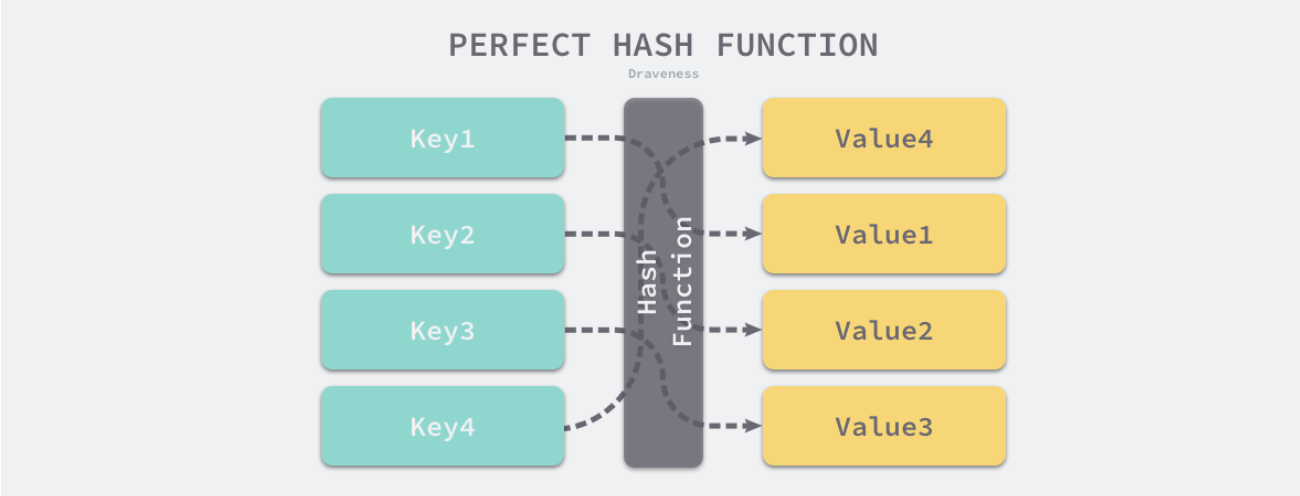
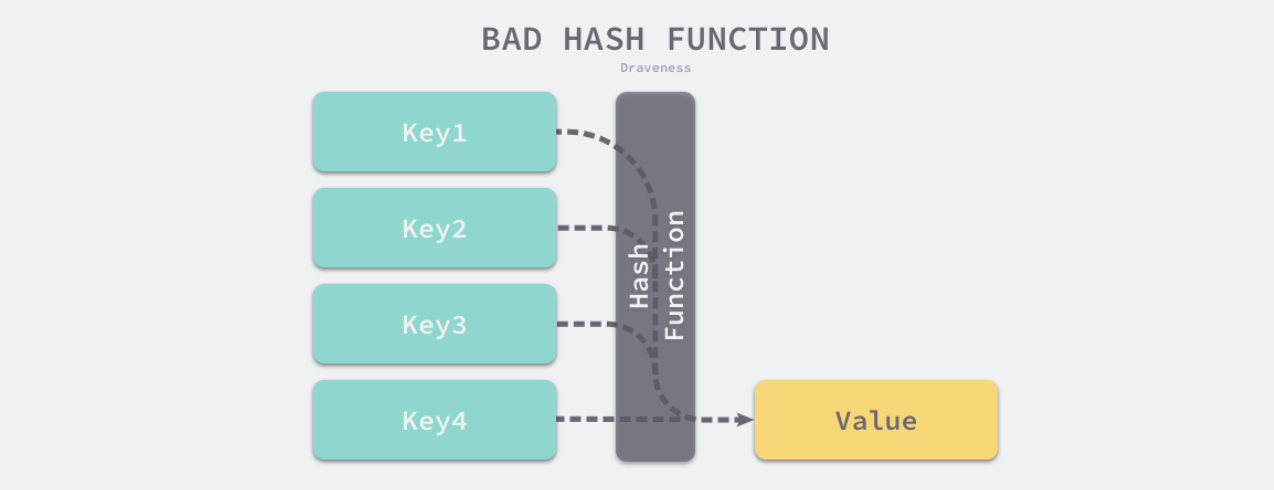
不同的键通过哈希函数产生相同的哈希值,就是我们常听到的哈希碰撞(哈希冲突)。
如果将 2450 个键随机分配到 100万 个桶中,则根据概率计算,至少有两个键被分配到同一个桶中的可能性有惊人的
95%。
哈希碰撞导致同一个桶中可能存在多个元素,有多种方式可以避免哈希碰撞,一般有两种主要的策略:拉链法和开发寻址法。
3.拉链法
3.1 设计原理
概念:将同一个桶中的元素通过链表的形式进行链接。 优点:随着同种元素的增加,可以不断链接新的元素,同时不用预先为元素分配内存。 缺点:需要存储额外的指针用于连接元素,这增加了整个哈希表的大小。同时由于链表存储的地址不连续,所以无法高效利用CPU高速缓存。
3.2 写入动画
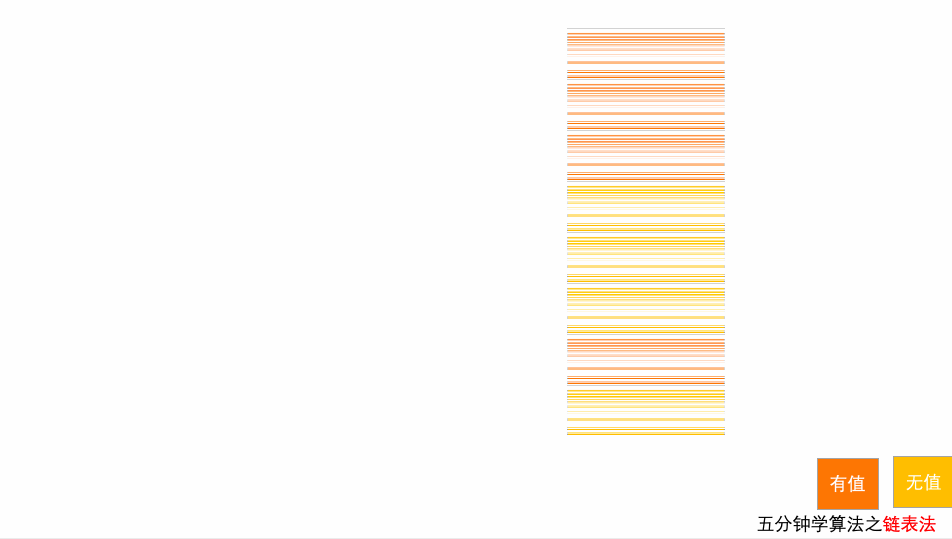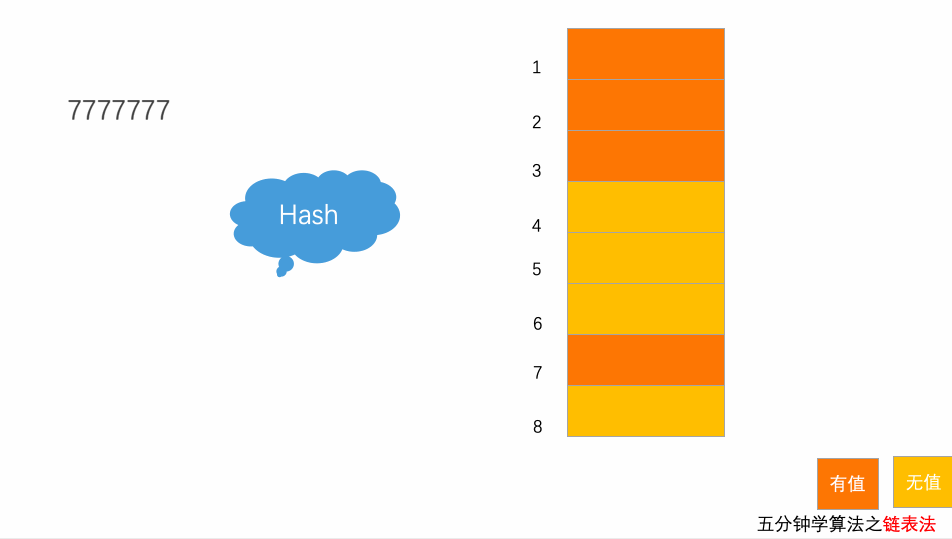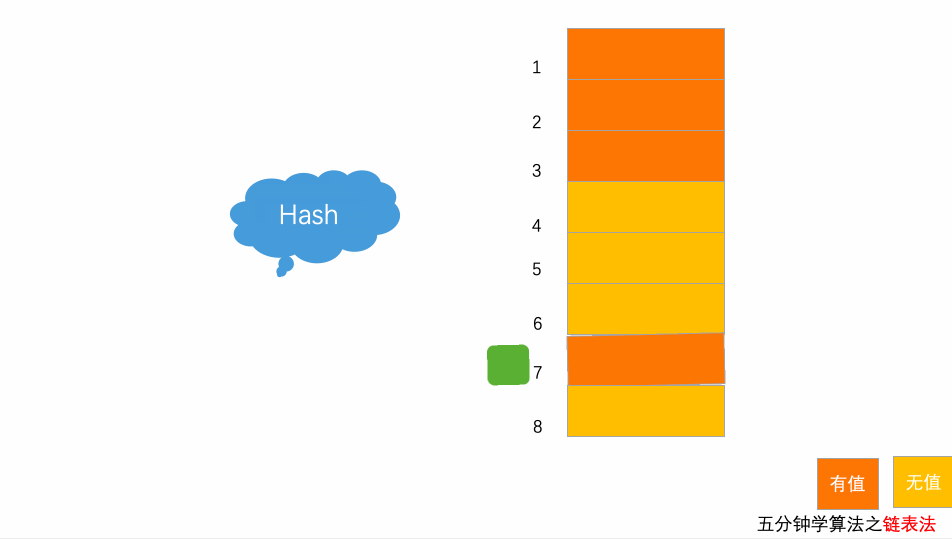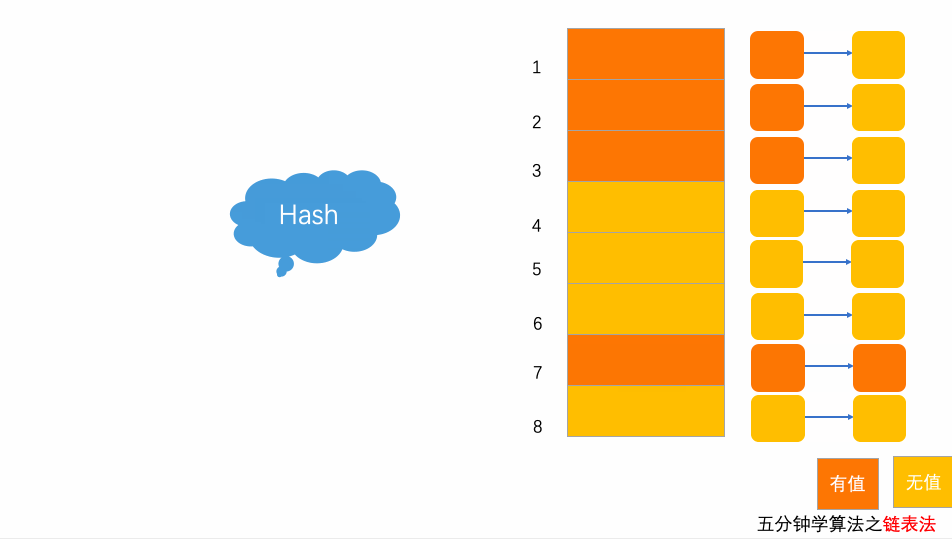
以上图为例,插入元素7777777,经过hash算法之后,被散列到位置下标为7的位置,但是这个位置已经有数据了,所以就产生了冲突,然后通过拉链的形式,挂载在后面。
4.开放寻址法
4.1 设计原理
概念:开放寻址法是一种在哈希表中解决哈希碰撞的方法,这种方法的核心思想是 依次探测和比较数组中的元素以判断目标键值对是否存在于哈希表中。
优点:由于存储的地址连续,可以更好地利用CPU高速缓存。
缺点:当散列表中插入的数据越来越多时,散列冲突发生的可能性就会越来越大,空闲位置会越来越少,线性探测的时间就会越来越久。极端情况下,需要从头到尾探测整个散列表,所以最坏情况下的时间复杂度为O(n)。
@注:Go语言中的哈希表采用的是开放寻址法中的线性探测(Linear Probing)策略。
开放寻址法中对性能影响最大的是装载因子,它是数组中元素的数量与数组大小的比值,随着装载因子的增加,线性探测的平均用时就会逐渐增加,这回影响哈希表的读写性能。当装载率超过70%后,哈希表的性能就会急剧下降,而一旦装载率达到100%,整个哈希表就会完全失效,这是查找和插入任意元素的时间复杂度都是
O(n),这是需要遍历数组中的全部元素,所以在实现哈希表时,一定要关注装载因子的变化。
装载因子:在一个性能比较好的哈希表中,每一个桶中都应该有 0~1 个元素,有时会有 2~3 个,很少会超过这个数量。计算哈希、定位桶和遍历链表 三个过程是哈希表读写操作的主要开销,公式:
装载因子 = 元素数量/桶数量
4.2 写入动画
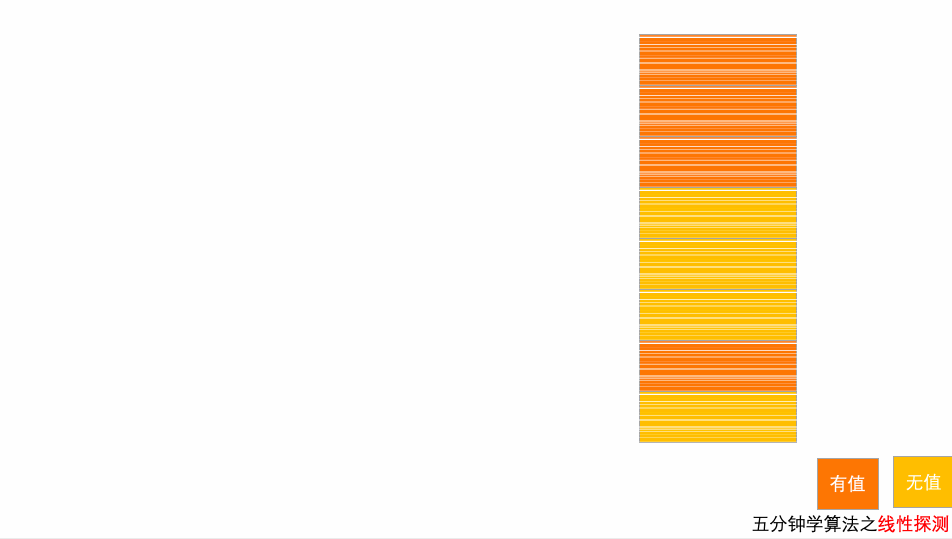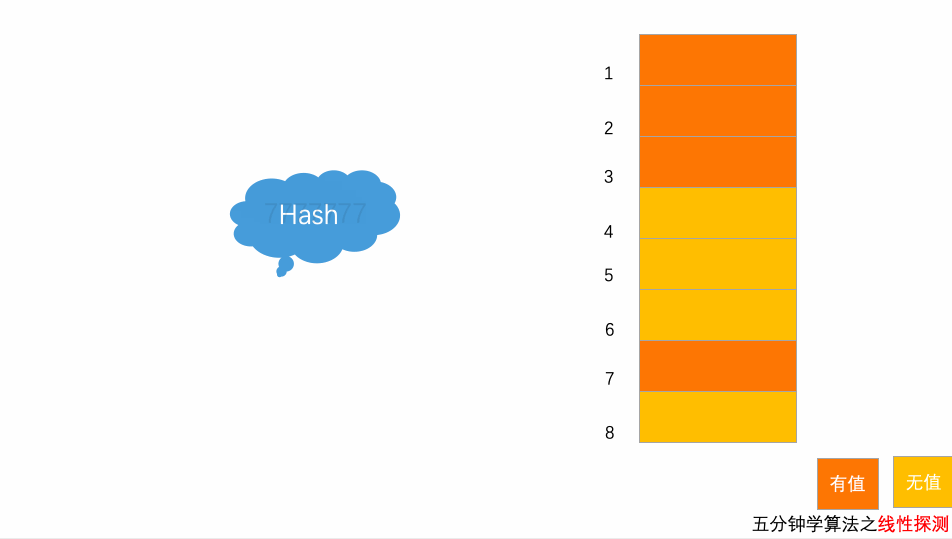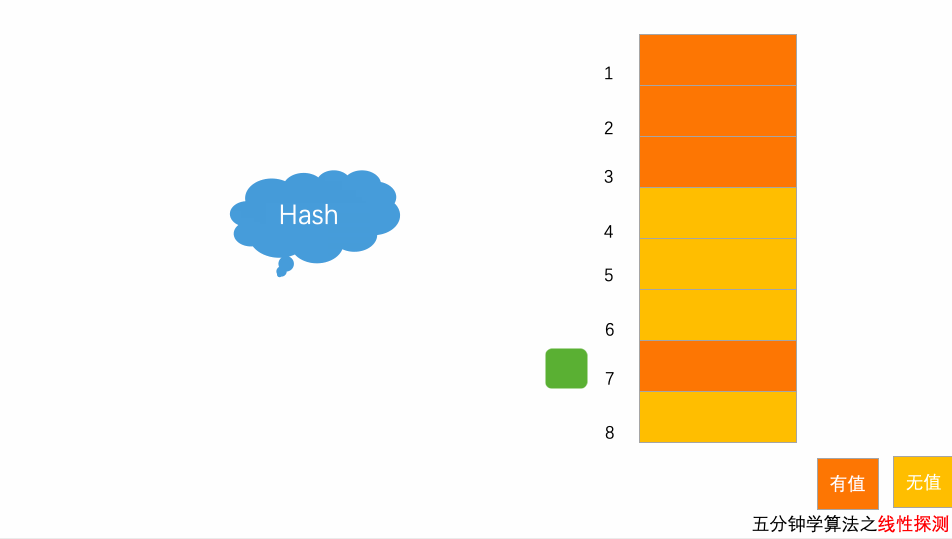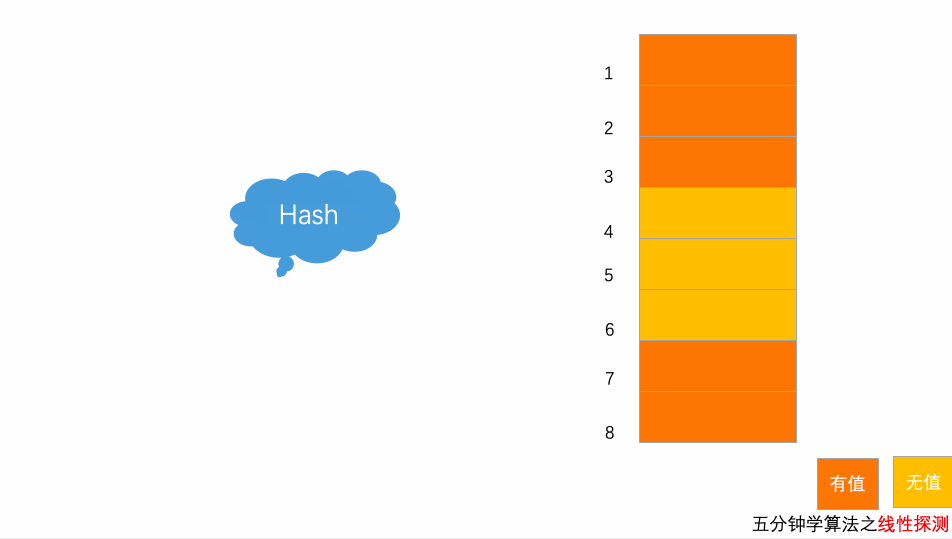
以上图为例,散列表的大小为8,黄色区域表示空闲位置,橙色区域表示已经存储了数据。目前散列表中已经存储了4个元素,此时元素7777777经过hash算法之后,被散列到位置下标为7的位置,但是这个位置已经有数据了,所以就产生了冲突,于是按顺序往后一个一个地找,看有没有空闲的位置,此时,运气很好,正巧在下一个位置就有空闲位置,将其插入,完成了数据存储。
5.并发冲突
和其他语言不同的是,map并不支持并发的读写,map并发读写是初级开发者经常会犯的错误。下面的示例,协程并发读写会报错为:fatal error:concurrent map read and map write。
5.1 错误示例
|
|
5.2 不支持并发读写的原因
Go语言为什么不支持并发的读写,是一个频繁被提起的问题,我们可以在Go官方文档中找到问题的答案。
官方文档的解释是:“map不需要从多个Goroutine安全访问,在实际情况下,map可能是某些已经同步的较大数据结构或计算的一部分。因此,要求所有map操作都互斥将减慢大多数程序的速度,而只会增加少数程序的安全性。",即Go语言只支持并发读写的原因是 保证大多数场景下的查询效率。
6.数据结构
6.1 核心结构体
Go语言运行时同时使用了多个数据结构组合表示哈希表,其中runtime.hmap是最核心的结构体,我们先来了解下该结构体的内部字段。
|
|
count: 表示当前哈希表中的元素数量。flags:表示当前map的状态(是否处于正在写入的状态等)。B:表示当前哈希表持有的buckets数量,但是因为哈希表中桶的数量都是2的倍数,所以该字段存储的是指数,即len(buckets) = 2^B。noverflow:代表当前map中溢出桶的数量,当溢出的桶太多时,map会进行扩容,其实质是避免溢出桶过大导致内存泄漏。hash0:是哈希的种子,它能为哈希函数的结果引入随机性,这个值在创建哈希表时确定,并在调用哈希函数时作为参数传入。buckets:指向当前map对应的桶的指针。oldbuckets:哈希在扩容时,用于保存之前buckets的字段,它的大小是当前buckets的一半,当所有旧桶中的数据都已经转移到了新桶中时,则清空。nevacuate:在扩容时使用,用于标记当前旧桶中小于nevacuate的数据都已转移到了新桶中。extra:存储map中的溢出桶。
6.2 结构示意图
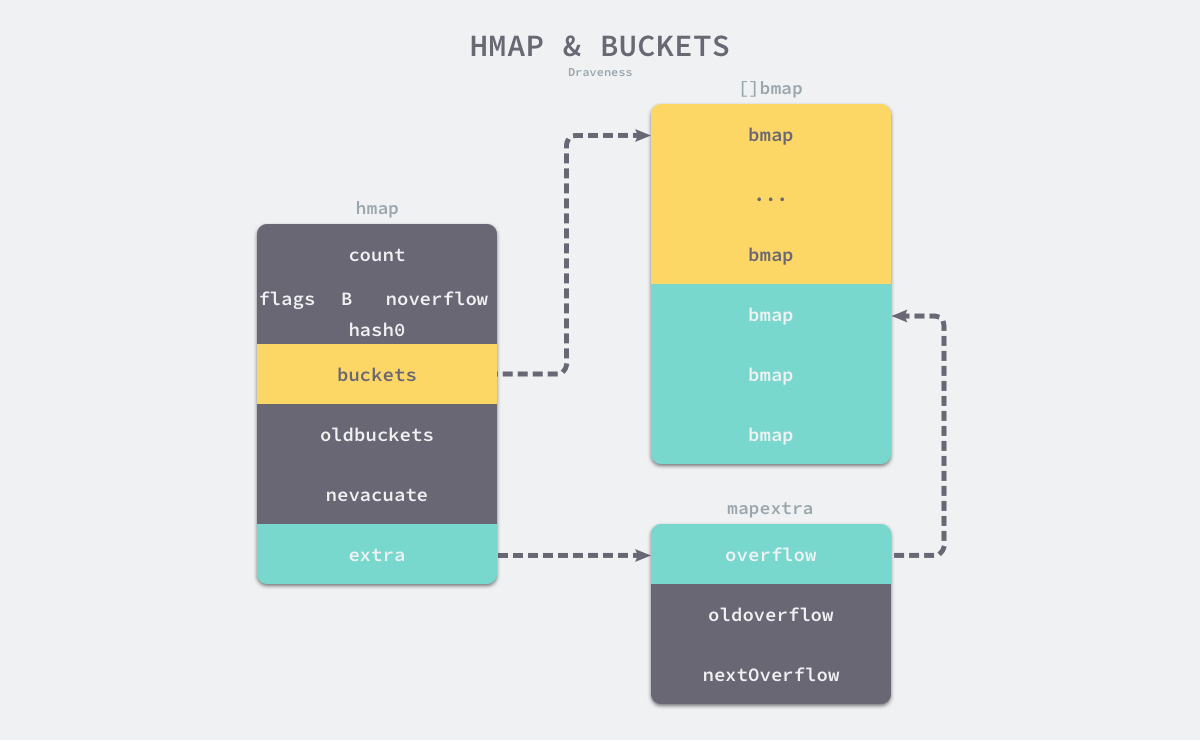
如上图所示,哈希表runtime.hmap的桶是runtime.bmap,每一个runtime.bmap都能存储8个键值对,当哈希表中存储的数据过多,单个桶已经装满时就会使用extra.nextOverflow中的桶存储溢出的数据。
上述两种不同的桶在内存中是连续存储的,我们在这里将它们分别称为 正常桶和溢出桶,上图中黄色的
runtime.bmap就是正常桶,绿色的runtime.bmap是溢出桶,溢出桶是在Go语言还是用C语言实现时使用的设计,由于它能够减少扩容的频率,所以一直使用至今。
6.3 桶结构(bmap)
代表桶的bmap结构在运行时只列出了首个字段,即一个固定长度为8的数组,此字段顺序存储key的哈希值的前8位。
|
|
1.桶中存储的key和value到哪儿去了?
在运行期间,runtime.bmap结构体其实不止包含tophash字段,因为哈希表中可能存储不同类型的键值对,而且Go语言当时也不支持泛型,所以键值对占据的内存空间大小只能在编译时进行推导,runtime.bmap中的其它字段在运行时也是通过计算内存地址的方式访问的,所以它的定义中就不包含这些字段,不过我们能根据编译期间的cmd/compile/internal/gc.bmap函数重建它的结构。
|
|
随着哈希表存储的数据逐渐增多,我们会扩容哈希表或者使用额外的桶存储溢出的数据,不会让单个桶中的数据超过
8个,不过溢出桶只是临时的解决方案,创建过多的溢出桶最终也会导致哈希的扩容。
7.初始化
7.1 字面量初始化
目前的现代编程语言基本都支持使用字面量的方式初始化哈希,一般都会使用key: value的语法来表示键值对,Go语言中也不例外:
|
|
我们需要在初始化哈希时声明键值对的类型,这种使用字面量初始化的方式最终都会通过 cmd/compile/internal/gc.maplit 初始化,我们来分析一下该函数初始化哈希的过程:
1.元素数量小于等于25时:
当哈希表中的元素数量<=25个时,编译器会将字面量初始化的结构体转换成以下的代码,将所有的键值对一次加入到哈希表中:
|
|
这种初始化的方式与数组和切片几乎完全相同,由此看来集合类型的初始化在Go语言中有着相同的处理逻辑。
2.元素数量大于25时:
一旦哈希表中元素的数量超过了25个,编译器会选择两个数组分别存储键和值,这些键值对会通过如下的for循环加入哈希:
|
|
使用字面量初始化的过程都会使用
Go语言中的关键字make来创建新的哈希并通过最原始的[]语法向哈希追加元素。
7.2 运行时
当创建的哈希被分配到栈上并且其容量小于BUCKETSIZE = 8时,Go语言在编译阶段会使用如下方式快速初始化哈希,这也是编译器对小容量哈希做的优化:
|
|
除了上述特定的优化之外,无论make是从哪里来的,只要我们使用make创建哈希,Go语言编译器都会在类型检查期间将它们转换成runtime.makemap,使用字面量初始化哈希也只是语言提供的辅助工具,最后调用的都是runtime.makemap:
|
|
这个函数会按下面的步骤执行:
- 计算哈希占用的内存是否溢出或者超出能分配的最大值
- 调用
runtime.fastrand来获取一个随机的哈希种子 - 根据传入的
hint计算出最小需要的桶的数量 - 使用
runtime.makeBucketArray创建用于保存桶的数组
8.读写原理
8.1 读取
在编译的类型检查期间,hash[key]以及类似的操作都会被转换成哈希的OINDEXMAP操作,中间代码生成阶段会在cmd/compile/internal/gc.walkexpr 函数中将这些OINDEXMAP操作转换成如下的代码:
|
|
赋值语句左侧接收参数的个数会决定使用的运行时方法:
- 当接受一个参数时,会使用
runtime.mapaccess1,该函数仅会返回一个指向目标值的指针; - 当接受两个参数时,会使用
runtime.mapaccess2,除了返回目标值之外,它还会返回一个用于表示当前键对应的值是否存在的bool值;
runtime.mapaccess1会先通过哈希表设置的哈希函数、种子获取当前键对应的哈希,再通过runtime.bucketMask和runtime.add拿到该键值对所在的桶序号和哈希高位的 8 位数字
runtime.mapaccess1源码:
|
|
在bucketloop循环中,哈希会依次遍历正常桶和溢出桶中的数据,它会先比较哈希的高 8 位和桶中存储的 tophash,Go语言采用了一种简单的方式hash&m计算出key应该位于哪一个桶中。获取桶的位置后,tophash(hash)计算出hash的前8位。接着此hash挨个与存储在桶中的tophash进行对比。如果有hash值相同,则会找到此hash值对应的key值并判断是否相同。如果key值也相同,则说明查找到了结果,返回value。
看图加深理解:
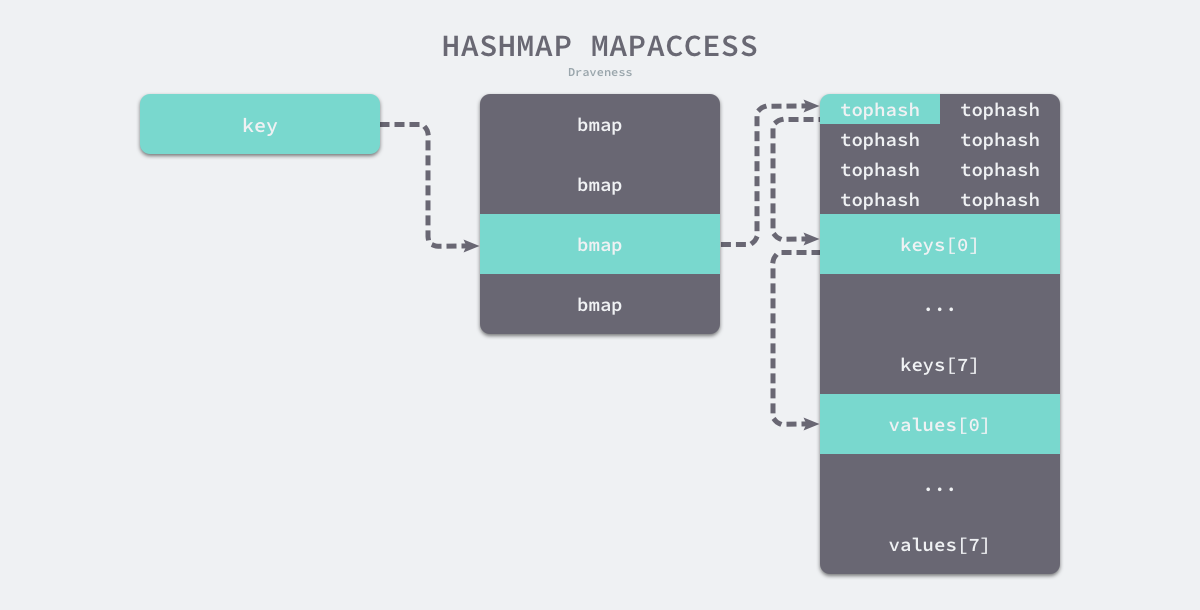
如上图所示,每一个桶都是一整片的内存空间,当发现桶中的 tophash 与传入键的 tophash 匹配之后,我们会通过指针和偏移量获取哈希中存储的键 keys[0] 并与 key 比较,如果两者相同就会获取目标值的指针 values[0] 并返回。
8.2 写入
当形如hash[key]的表达式出现在赋值符号左侧时,该表达式也会在编译期间转换成 runtime.mapassign 函数的调用,该函数与 runtime.mapaccess1 比较相似,我们将其分成几个部分依次分析,首先是函数会根据传入的键拿到对应的哈希和桶:
src/runtime/map.go:578
|
|
然后通过遍历比较桶中存储的 tophash 和键的哈希,如果找到了相同结果就会返回目标位置的地址,获得目标地址之后会通过算术计算寻址获得键值对 k 和 val:
src/runtime/map.go:619
|
|
桶满后存到溢出桶:
如果当前桶已经满了,哈希会调用 runtime.hmap.newoverflow 创建新桶或者使用 runtime.hmap 预先在 noverflow 中创建好的桶来保存数据,新创建的桶不仅会被追加到已有桶的末尾,还会增加哈希表的 noverflow 计数器。
src/runtime/map.go:662
|
|
文章作者 Learn Go
上次更新 2023-07-12